Im ersten Teil dieses Blogbeitrags hatte ich angekündigt, noch über einige interessante Vorträge zu berichten, die ich in Frankfurt gehört habe - jetzt finde ich endlich die Zeit dafür. Die Zahl der auf den OPUS-Server hochgeladenen Volltexte in der Sammlung zum diesjährigen Bibliothekartag hat sich mittlerweile auf 205 erhöht - leider fehlen aber immer noch bei manchen Beiträgen die Folien. Bitte, liebe Vortragende, laden Sie Ihre Präsentation rasch hoch, wenn Sie dies noch nicht getan haben!

Mit Open Source die Aufsatzkatalogisierung reformieren
Dies war der Titel eines Vortrags von Timotheus Kim (UB Tübingen). Er ist für eine große theologische Fachbibliographie, den IxTheo (Index Theologicus), zuständig. Seit einiger Zeit werden die IxTheo-Daten im SWB gehalten. Gemeinsam mit Philipp Zumstein (UB Mannheim) hat Herr Kim eine Methode entwickelt, mit der sich die Katalogisierung von Aufsätzen radikal vereinfachen lässt, sofern im Web bibliografische Metadaten vorliegen.
Anstatt Angaben abzutippen oder mühsam einzelne Teile per Copy & Paste zu übertragen, werden die Daten zunächst in Zotero heruntergeladen. Für dieses Literaturverwaltungsprogramm wurde eine spezielle Erweiterung zur Nutzung in der Katalogisierung (zotkat) programmiert - natürlich als Open Source, um eine Anpassung und Nachnutzung zu ermöglichen. Kern des Workflows ist die Umsetzung der Metadaten ins Pica-Format auf Knopfdruck. Auch die Herstellung der korrekten Verlinkung zum Normdatensatz für den Autor wird durch das System unterstützt. Die vorhandenen Daten werden außerdem in verschiedener Hinsicht angereichert. Die Details kann man in einem im vergangenen Jahr in der Open-Access-Zeitschrift Libreas erschienenen Aufsatz nachlesen. Es gibt außerdem ein Video, auf dem man sich den Workflow ansehen kann (verlinkt sowohl in den Vortragsfolien als auch im Aufsatz).
Halbautomatische Methoden wie die gerade beschriebene "Aufsatzkatalogisierungsreform" (oder ist es schon eine "Revolution"?) ermöglichen eine hohe Rationalisierung, ohne die Qualität zu gefährden. Denn es ist ja immer noch ein Mensch involviert, der die Daten prüft und ggf. korrigieren kann. Vielleicht ist dies der Königsweg für die Erschließung - zumindest für den Kernbereich der in Bibliotheken gesammelten bzw. nachgewiesenen Ressourcen? Leider läuft es derzeit vielfach eher in Richtung Vollautomatisierung, wie auch das jüngst veröffentlichte neue DNB-Konzept zur Inhaltserschließung zeigt.
Von der Schneeflocke zur Lawine: Möglichkeiten der Nutzung freier Zitationsdaten in Bibliotheken
Bleiben wir noch kurz im Umfeld der UB Mannheim, die m.E. schon seit längerer Zeit zu den innovativsten Bibliotheken in Deutschland gehört und immer wieder wichtige Impulse setzt. Annette Klein und der gerade schon genannte Kollege Zumstein sind hier in dem spannenden DFG-Projekt "Linked Open Citation Database" aktiv. Zu den weiteren Beteiligten gehört übrigens - neben der ZBW und dem Deutschen Forschungszentrum für Künstliche Intelligenz in Kaiserslautern - auch die HdM, vertreten durch meinen Kollegen Kai Eckert (der ja auch aus der "Mannheimer Schule" kommt). Frau Klein stellte das Projekt in einem Vortrag vor; weitere Informationen findet man auf der Projekthomepage.
Die Vision des Projekts ist die Schaffung einer "verteilten Infrastruktur für offene Zitationen" auf der Basis von Linked Open Data. Einerseits sollen dafür vorhandene Daten, z.B. aus Open Citations, genutzt werden. Andererseits werden aber auch Tools entwickelt, um aus Scans von Literaturverzeichnissen weitere Zitationsdaten zu generieren - hier könnten Bibliotheken eine wichtige Rolle spielen. Automatisch können in der Regel Namen von Verfassern, Titel, Erscheinungsjahre u.a. erkannt werden; im Bedarfsfall soll intellektuell korrigiert werden. In Kombination mit unseren Nachweisdatenbanken dürfte über diese Informationen eine gesicherte Zuordnung in den allermeisten Fällen problemlos möglich sein.
Bei Zitationen denkt man üblicherweise zuerst an Bibliometrie, Impact-Faktoren etc. - Dinge, die normale Nutzer nicht interessieren. Aber Zitationsbeziehungen haben auch ein erhebliches Potenzial für Recherche und Erschließung. Das "Schneeballsystem" ist uns allen wohl bekannt: Im Literaturverzeichnis eines gefundenen relevanten Werkes kann man üblicherweise weitere relevante Werke finden. Diese Methode führt freilich immer nur rückwärts in der Zeit, hin zu älterer Literatur. Mindestens genauso nützlich wäre es zu wissen, welche später erschienenen Werke das gerade vorliegende relevante Werk zitieren.
In Ansätzen ist dies seit letztem Jahr im Katalog der UB Mannheim umgesetzt, denn Primo Central bietet solche Informationen basierend auf dem "Cited by"-Dienst von CrossRef. Berücksichtigt werden hier allerdings nur Ressourcen, die über einen DOI verfügen, und auch da nur ein bestimmter Ausschnitt (z.B. kaum Lehr- und Handbücher). Die Zahl scheint noch gering zu sein: Wie Frau Klein berichtete, musste sie länger nach einem Beispiel suchen (Folie 7).
Dass zwischen dem zitierenden Werk und den zitierten Werken inhaltliche Beziehungen stehen, liegt auf der Hand. Man kann aber auch von inhaltlichen Ähnlichkeiten zwischen mehreren Werken ausgehen, die eine große Überschneidung bei der zitierten Literatur haben. Entsprechend wäre es hilfreich, wenn im Katalog solche Werke als "vielleicht auch von Interesse" angezeigt würden. Die Auswertung von Zitationsbeziehungen könnte außerdem den Verfahren in der automatischen Erschließung eine ganz neue Dimension hinzufügen. Vermutlich könnte man damit recht zuverlässig zumindest eine grobe fachliche Zuordnung eines Werks erreichen. Ich glaube sogar, dass diese Methode zu besseren Ergebnissen führen würde als die derzeit in der DNB erprobte "Fingerprint"-Technik. Bei dieser wird versucht, die zutreffende Sachgruppe eines Werks aus den Systemstellen der dafür maschinell vergebenen GND-Schlagwörter abzuleiten (vgl. dazu den Vortrag von Elisabeth Mödden auf dem Workshop zur computerunterstützten Inhaltserschließung in Stuttgart, Folien 25-27).
Erweiterung des Suchvokabulars für "schlechte" Daten
Eine Sache, die mich schon lange interessiert, ist die Verbesserung von Suchergebnissen in Systemen, die heterogen erschlossene Daten enthalten und ohne Normdaten arbeiten, durch den Einsatz unserer bibliothekarischen Werkzeuge. Man kann sich etwa vorstellen, bei der Suche in einem Resource Discovery System die Benutzereingabe zu analysieren und auf der Basis von Normdateien oder Thesauri zusätzliche geeignete Suchbegriffe zu ermitteln - beispielsweise Varianten von Personennamen, Synonyme von Schlagwörtern oder verwandte Begriffe.
Ein System, das schon vor Jahren mit dieser Technik arbeitete, ist EconBiz. Früher konnte man sich die zusätzlichen Begriffe anzeigen lassen. Man sieht das noch in einem Screenshot von 2012, den ich mal für eine Präsentation gemacht habe:

Inzwischen funktioniert EconBiz offenbar anders; ich nehme aber an, dass immer noch mit Termerweiterung gearbeitet wird (wenn jemand Genaueres darüber sagen kann, bitte ich um einen Hinweis über die Kommentarfunktion). Vermutlich werden die zusätzlichen Begriffe jetzt entweder automatisch bei der Recherche hinzugespielt oder die Metadaten selbst werden vorab entsprechend angereichert. Letzteres ist sicher die bessere Methode, wenn man Zugriff auf die Daten selbst hat (was bei kommerziellen RDS ja in der Regel nicht der Fall ist).
In diesem Kontext fand ich den Vortrag von David Aumüller (UB Leipzig) mit dem Titel Normdaten suchen und finden - Anreicherung alternativer Schreibweisen in ein Discovery System am Beispiel einer Metadatenquelle ohne existierende Normdatenverlinkung interessant. Herr Aumüller testete das Matching von Komponistennamen, die in seinem Testkorpus vorkamen, mit der GND. In der Präsentation zeigte er auch einige Fallstricke auf; es ist nicht ganz simpel, das Matching richtig einzustellen. Leider habe ich mir die schönen Beispiele für Fehl-Matches nicht notiert, und die Folien sind noch nicht online. War das Matching erfolgreich, können die Namensvarianten aus der GND im Datensatz ergänzt werden.
Bemerkenswert fand ich auch, dass Herr Aumüller die GND-Daten nicht direkt verwendet, sondern über den "Umweg" Wikidata darauf zugegriffen hat (u.a. lobte er die vielfältigen Abfragemöglichkeiten, die er auf diesem Weg hatte). Das hat viele im Saal verblüfft, ist aber aus Sicht eines Kollegen, der viel im Web und mit Linked Data arbeitet, wahrscheinlich durchaus logisch. Frau Katz vom BSZ hat Herrn Aumüller natürlich sogleich zugesichert, ihm für künftige Arbeiten einen Vollabzug der GND in einer Form zur Verfügung zu stellen, mit der er gut arbeiten kann. Aber vielleicht sollten wir mal darüber nachdenken, ob die GND tatsächlich schon in der optimalen Form für eine breite Nachnutzung auch außerhalb des Bibliothekswesens zur Verfügung steht.
Semantischer Discovery Service Yewno
Besonders gespannt war ich auf den Vortrag von Berthold Gillitzer (BSB München) über ein - wie es in einem Blog-Beitrag der BSB vom Februar 2017 hieß - "zukunftsweisendes semantisches Recherchewerkzeug" mit dem Namen Yewno. Der Vortrag war im Wesentlichen eine verkürzte Fassung eines Aufsatzes von Herrn Gillitzer in ZfBB 2017, Heft 2. Das Live-Anhören war allerdings schon deshalb nützlich, weil ich nun nicht mehr rätseln muss, wie sich das Ding ausspricht - genauso wie "you know" ;-)
Berthold Gillitzer stellte in seinem Vortrag die "Fragmentierung" in der heutigen digitalen Welt heraus: Nutzer seien häufig nur an kleinen Ausschnitten eines längeren Texts interessiert. Die bibliothekarische Erschließung setze aber beim großen Ganzen an - erschließe also z.B. ein Buch als Ganzes und nicht die zahlreichen kleinteiligen Informationen darin. Diese Analyse ist sicher richtig - ich glaube allerdings, dass dies nichts wirklich Neues ist. Man musste doch auch früher öfter Nutzer an der Auskunft darauf hinweisen, dass es möglicherweise einfach nichts gibt, was sich ausschließlich mit ihrer sehr speziellen Frage beschäftigt; sie müssten deshalb nach etwas allgemeineren Werken suchen, in denen das Thema mitbehandelt wird. Klar ist natürlich, dass mit dem massenhaften Vorliegen von digitalen Volltexten neue Möglichkeiten entstehen, um den Zugang zum Inhalt einer Ressource auf einer anderen Granularitätsstufe zu ermöglichen (über eine banale Volltextsuche hinaus). Und sicher ist es auch richtig, dass Erschließung auf einer solchen Tiefe nicht mehr intellektuell geleistet werden kann.
Die spannende Frage ist nun, ob Systeme wie Yewno - das man an der BSB während einer Testphase hier ausprobieren kann - dabei einen entscheidenden Fortschritt bringen können (die Testphase geht offiziell nur bis zum heutigen 30. Juni; das System wird aber wohl in verbesserter Form weiter betrieben werden). Der Anspruch von Yewno ist, durch statistische Analysen der Volltexte Konzepte zu identifizieren. Die Details sind Geschäftsgeheimnis, aber das Grundprinzip ist ein altbekanntes. Ich zitiere aus dem Aufsatz (S. 74):
"Konzepte werden (…) durch diese Verfahren der statistischen Semantik extrahiert und bestimmten Textstellen in digitalen Dokument, wo es um diese Konzepte geht, zugeordnet. Die statistisch-semantischen Verfahren beruhen auf der sogenannten "distributional hypotheses [sic]" , wonach Wörter/Konzepte mit ähnlicher Bedeutung in ähnlichen Kontexten vorkommen. Das heißt, dass es eine Korrelation zwischen ähnlicher Verteilung von Wörtern in begrenzten Kontexten und ähnlicher Bedeutung gibt, die es gestattet vom einen auf das andere zu schließen."
Das zweite charakteristische Element von Yewno ist eine visuelle Darstellung des gesuchten Konzepts im Zusammenhang mit (irgendwie) verwandten Konzepten. Vielleicht erinnern sich manche noch an den "AquaBrowser", der vor einigen Jahren kurzzeitig en vogue war - Yewno sieht ganz ähnlich aus. Hier ein Screenshot meiner Suche nach "information literacy" (zum Vergrößern anklicken):

Ich muss gestehen, dass ich mit der angeblich völlig intuitiven Suche in Yewno überhaupt nicht zurecht gekommen bin. Für mich war wenig nachvollziehbar, was passiert, wenn ich irgendwo drauf klicke. Erst nach der Lektüre der Hinweise im Aufsatz von Herrn Gillitzer habe ich das etwas besser verstanden. Das mag aber daran liegen, dass ich kein sehr visueller Mensch bin. Herr Gillitzer berichtete außerdem, dass die Darstellung bald verbessert werden soll.
Ein großes Plus von Yewno soll sein, dass es Beziehungen zwischen Konzepten sichtbar macht, auf die man nicht unbedingt gekommen wäre und die auch in herkömmlichen Erschließungssystemen nicht berücksichtigt werden. In der Tat beschränken sich Thesauri auf hierarchische Beziehungen sowie verwandte Begriffe, was gewiss nur einen Teil der bestehenden Zusammenhänge abdeckt. Man könnte sich beispielsweise vorstellen, über ein System wie Yewno Beziehungen zwischen einem Thema und Personen, die für dieses Thema wichtig sind, zu entdecken. In der oben gezeigten Beispielsuche erscheinen tatsächlich drei Personen, von denen immerhin zwei Bibliothekare sind (Michael Gorman und William Andrew Moffett). Allerdings haben beide nach meinen Recherchen überhaupt nichts mit dem Thema Informationskompetenz zu tun, und ich rätsele - auch nach Begutachtung der in Yewno zu ihnen vorhandenen Dokumente - wie das System auf diesen Zusammenhang gekommen ist (bei Gorman finden sich immerhin die Wörter "information" und "literacy" im Wikipedia-Eintrag, aber natürlich getrennt). Auch der Zusammenhang bei Patricia Hogan erscheint alles andere als naheliegend. Ansonsten gibt es durchaus als verwandt gezeigte Konzepte, die in das engere oder weitere Umfeld der Informationskompetenz gehören - allerdings auch völlige Nieten wie "Reproductive rights". Um die Nützlichkeit der von Yewno entdeckten Zusammenhänge zu bewerten, genügen natürlich einige Testrecherchen nicht, sondern es müsste eine umfangreiche Evaluation erstellt werden. Ich hoffe, dass die BSB dies im Rahmen ihres Pilotversuchs tun wird.
Beim Herumspielen mit dem System fiel mir auf, dass man manchmal auch mit einer Abkürzung zum gesuchten Konzept kommt, manchmal aber nur mit der Vollform. Beispielweise kennt Yewno das Konzept "Resource Description and Access", aber nicht "RDA". Als ich beim Vortrag danach fragte, vermutete Herr Gillitzer, dass es einfach nicht genügend Dokumente zu RDA bei Yewno gebe. Es sind aber immerhin zehn Stück, und natürlich kommt immer auch die Abkürzung darin vor. Ich habe mittlerweile einen anderen Verdacht (dazu gleich mehr).
Ich habe Herrn Gillitzer in der Fragerunde zum Vortrag außerdem gefragt, ob es nicht sinnvoll wäre, für ein System wie Yewno auch Nutzen aus den vorhandenen bibliothekarischen Werkzeugen zu ziehen. Schließlich haben wir in der GND und in Fachthesauri mit viel intellektueller Mühe Synonyme gesammelt und Beziehungen zwischen Konzepten dokumentiert (auch wenn diese nur einen Teil des breiteren "Konzept-Feldes" abdecken, auf das Yewno abzielt). Herr Gillitzer konnte sich dies durchaus vorstellen, bekam aber von einem im Publikum sitzenden Kollegen kräftig Kontra: Es wäre ganz schlecht, wenn man wieder intellektuell erstellte Daten mit ins Spiel bringen wollte; es wäre viel besser, sich ausschließlich auf die künstliche Intelligenz zu verlassen.
Kommen wir nun vor diesem Hintergrund noch einmal zurück zu der Geschichte mit den Abkürzungen. Nach einigen Stichproben habe ich mich gefragt, ob Yewno sich die Verweisungen nicht einfach aus der amerikanischen Wikipedia holt. Bei Seiten, bei denen oben eine "Redirect"-Info von der Abkürzung angegeben ist (z.B. International Organization for Standardization/ISO, American National Standards Institute/ANSI, Federal Bureau of Investigation/FBI), funktionierte nämlich die Suche sowohl mit Lang- als auch mit Kurzform, aber nicht bei Seiten ohne einen solchen Vermerk (z.B. Library of Congress/LoC, Resource Description and Access/RDA, Resource Description Framework/RDF). Um diesen Verdacht zu verifizieren oder falsifizieren, müsste man aber natürlich mehr Fälle prüfen (und auch nicht in der Wikipedia selbst, sondern wohl in der DBpedia - ich kenne mich damit aber nicht so aus). Vielleicht mag sich das mal jemand von unseren Wikipedianern näher ansehen.
Gestutzt habe ich auch, als ich bei der Eingabe von "Michael Gorman" diese Anzeige bekam. Beachten Sie den ersten Treffer, bei dem es sich ganz offensichtlich um eine Disambiguierungsseite aus der Wikipedia handelt:
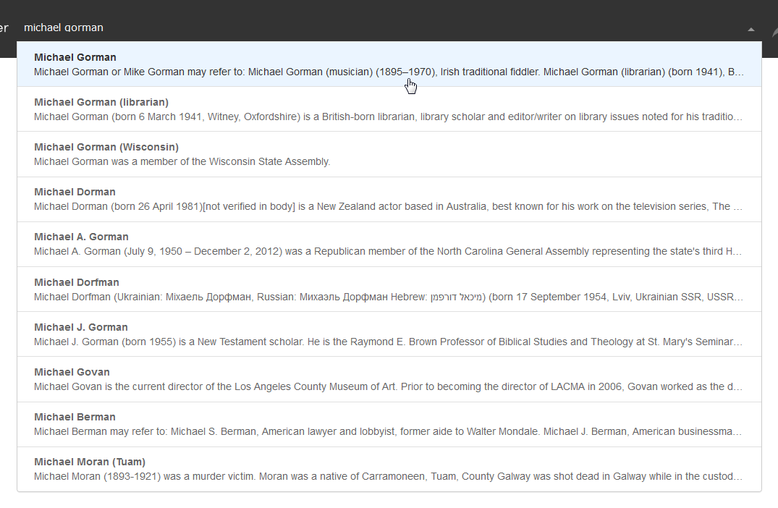
Wählt man dieses "Pseudo-Konzept" aus, so vermeldet das System: "At the moment we don't have enough content about this topic to guarantee you relevant results. We index new books and articles every week, so please check back soon." Mal sehen, wann die vielgelobte künstliche Intelligenz lernen wird, dass es zu derartigen Treffern niemals Ergebnisse geben wird... Stichproben ergaben jedenfalls einige weitere Treffer desselben Typs (z.B. "John May", "May Lake", "Scott Mayer"), aber es ist auch nicht so, dass man jede derartige Disambiguierungsseite auf Yewno als Konzept finden würde. Vielleicht gibt es hier einen Filtermechanismus, der aber nicht immer sauber funktioniert.
Ich will ja kein Spielverderber sein, aber nach diesen Eindrücken frage ich mich doch, ob die Identifizierung von Konzepten durch Yewno wirklich alleine auf einer statistischen Analyse der Volltexte beruht - oder womöglich in erster Linie aus einer Nachnutzung der Wikipedia? Natürlich kann man argumentieren, dass die Wikipedia eben auch Volltexte zur Verfügung stellt, die von Yewno mit Textmining-Methoden behandelt werden können. Aber die Besonderheit der Wikipedia-Artikel ist doch, dass sie jeweils für ein Konzept stehen - insofern haben sie eine gewisse Ähnlichkeit mit Thesauri. Falls dem tatsächlich so wäre, würde dann Yewno nicht doch - entgegen dem eigenen Anspruch - in erheblichem Maße von der intellektuellen Arbeit von Menschen (den Wikipedianern) profitieren? Oder habe ich hier irgendwo einen Denkfehler?
Vielleicht können Herr Gillitzer und andere KollegInnen, die tiefer in das Yewno-System eingestiegen sind, dazu noch ein bisschen was erläutern (nutzen Sie gerne die Kommentarfunktion). Und gewiss wird es spannend zu beobachten sein, wie es mit Yewno weitergehen wird. Auf der Seite werden jedenfalls "exciting new changes" angekündigt:
Jetzt habe ich zwar nur vier Vorträge vorgestellt und kommentiert, aber ich denke, dass sie einigen Stoff zum Nachdenken und Diskutieren geben. Ich bin gespannt auf Ihre Kommentare! Gerne können Sie darin auch auf weitere spannende Vorträge hinweisen.
Heidrun Wiesenmüller
Kommentar schreiben
Tamara Pianos (Dienstag, 04 Juli 2017 08:57)
Liebe Frau Wiesenmüller,
Zur Erweiterung des Suchvokabulars in EconBiz: Im Jahr 2012 konnten die Suchwörter durch einen eingebundenen Webservice erweitert werden. Dieser war für die von Ihnen beschriebenen Zwecke prinzipiell sehr gut geeignet, hatte aber zwei Nachteile. Einerseits gab es bei bestimmten Suchbegriffen sehr viele OR-Verknüpfungen, so dass die Suche ggf. aufgebläht wurde. Zum anderen konnte man damit immer nur einen Suchbegriff zu Zeit erweitern. In Ihrem Beispielfall also Krankenversicherung OR health insurance etc. Hätte ich das Ganze aber verbinden wollen mit einer Suche nach Deutschland OR Germany etc. wäre das auf diesem Wege nicht möglich gewesen.
Deshalb reichern wir mittlerweile – wie Sie richtig vermuten – die inhaltsbeschreibenden Metadaten in Form einer Indexerweiterung an. Dies geschieht allerdings bislang nur dort wo wir einen Ansatzpunkt über eine ID haben, etwa bei GND-Schlagwörtern im Indexat. Somit greift dieses Verfahren momentan leider nicht für die in Ihrer Überschrift genannten „schlechten“ Daten. Da hoffe ich noch auf Optimierungspotential in der Zukunft.
Viele Grüße
Tamara Pianos